Таблица кодировки ansi русские буквы. Что такое кодировка ANSI и с чем ее едят? Перевод единиц давления из ANSI в DIN
Прежде чем отвечать на вопрос о том, что же такое кодировка ANSI Windows, ответим сначала на другой вопрос: "Что же такое кодировка вообще?"
У каждого компьютера, в каждой системе используется определенный набор символов, зависящий от языка, используемого пользователем, от его профессиональных компетенций и личных предпочтений.
Общее определение кодировки
Так, в русском языке используется 33 символа для обозначения букв, в английском - 26. Также используется 10 цифр для счета (0; 1; 2; 3; 4; 5; 6; 7; 8; 9) и некоторые специальные символы, минус, пробел, точка, процент и так далее.
Каждому из этих символов при помощи кодовой таблицы присваивается порядковый номер. К примеру, букве "A" может быть присвоен номер 1; "Z" - 26 и так далее.
Собственно, номер, представляющий символ как целое число, считается кодом символа, а кодировка - это, соответственно, набор символов в такой таблице.
Богатство разнообразия кодовых таблиц
На данный момент существует довольно большое количество кодировок и кодовых таблиц, используемых разными специалистами: это и ASCII, разработанная в 1963 году в Америке, и Windows-1251, совсем недавно еще бывшая популярной благодаря Microsoft, KOI8-R и Guobiao - и многие, многие другие, причем процесс их появления и отмирания происходит и по сей день.
Среди этого огромного списка совершенно особо держится так называемая кодировка ANSI.
Дело в том, что в свое время компания Microsoft создала целый набор кодовых страниц:
Все они получили общее название таблицы кодировки ANSI, или кодовой страницы ANSI.
Интересный факт: одной из первых кодовых таблиц стала ASCII, в 1963 году созданная American National Standards Institute (Американским национальным институтом стандартов), сокращенно называвшимся именно ANSI.
Помимо всего прочего, эта кодировка содержит и непечатные символы, так называемые "Управляющие последовательности", или ESC, уникальные для всех таблиц символов, зачастую несовместимые между собой. При умелом использовании, однако, они позволяли скрывать и восстанавливать курсор, переводить его с одного положения в тексте на другое, устанавливать табуляцию, стирать часть окна терминала, в котором велась работа, изменять форматирование текста на экране и менять цвет (или даже рисовать и подавать звуковые сигналы!). В 1976 году, кстати, это было довольно неплохим подспорьем для программистов. Кстати, терминал - это устройство, требующееся для ввода и вывода информации. В те далекие времена он представлял собой монитор и клавиатуру, подсоединенные к ЭВМ (электронной вычислительной машине).
Некорректное отображение символов
К сожалению, в дальнейшем подобная система вызвала многочисленные сбои в системах, выводя вместо желаемых стихов, лент новостей или описаний любимых компьютерных игр так называемые кракозябры - бессмысленные, нечитаемые наборы символов. Появление этих вездесущих ошибок было вызвано всего лишь попыткой отображать символы, закодированные в одной кодовой таблице, при помощи другой.

Чаще всего с последствиями неверного чтения этой кодировки мы сталкиваемся в Интернете до сих пор, когда наш браузер по какой-то причине не может достаточно точно определить, какая именно из Windows-**** кодировок используется в данный момент, из-за указания веб-мастером общей кодировки ANSI либо изначально неверной кодировки, к примеру, 1252 вместо 1521. Ниже представлена точная таблица кодировок.
Кириллическая таблица ANSI-кодировок, Windows-1251
Более того, в 1986 году ANSI была существенно расширена, благодаря Яну Э. Дэвису, написавшему пакет The Draw, позволяющий не просто использовать базовые, с нашей точки зрения, функции, но и полноценно (или почти полноценно) рисовать!

Подводя итоги
Таким образом, можно видеть, что кодировка ANSI, по сути, хоть и была довольно спорным решением, сохраняет свои позиции.

Со временем с легкой руки энтузиастов древний терминал ANSI перекочевал даже на телефоны!
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
*Наведите курсор мыши для приостановки прокрутки.
Назад Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров , т.е. нечитаемых символов.
Итак, поехали...
Что такое кодировка?
Упрощенно говоря, кодировка - это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов , которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII .
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка , в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.

Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков , помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R - это тоже расширенная кодировка ASCII , предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок .
По сути это были те же расширенные версии ASCII , однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало "свободных мест".
Примером такой ANSI-кодировки является всем известная Windows-1251 . Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
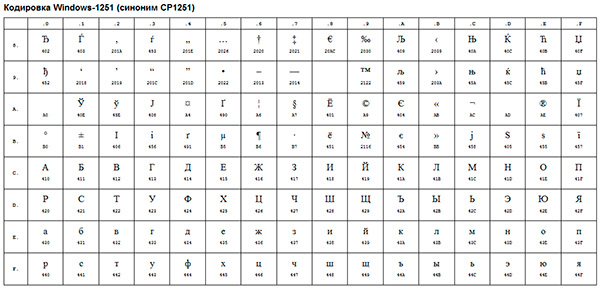
ANSI-кодировка - это собирательное название . В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами - нечитаемым бессмысленным набором символов.
Причина их появления проста - это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу .
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере .
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст - вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда .
Юникод - универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32 .
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита , т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов , что "утяжеляет" файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка - UTF-16 .
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое "легче", чем в UTF-32, однако и вдвое "тяжелее" любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального , и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 - это многобайтовая кодировка с переменной длинной символа . Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII . Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет "тратить" на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не "утяжеляя" без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++ , phpDesigner , rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
ANSI
- UTF-8
- UTF-8 без BOM
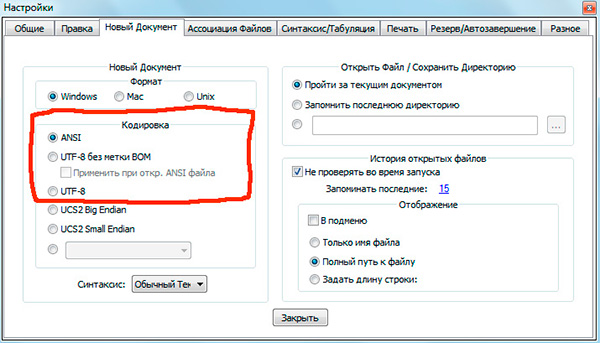

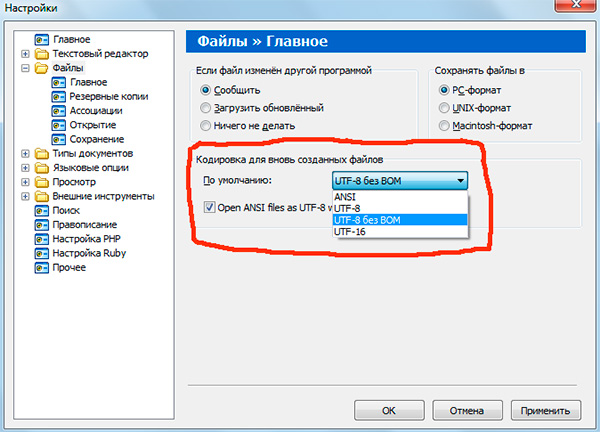
Сразу скажу, что выбирать всегда стоит именно последний вариант - UTF-8 без BOM .
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark . Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM . Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом , в результате чего возникают ошибки в работе скриптов.
Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн .
Таблица ASCII
ASCII (American Standard Code for Information Interchange)
Сводная таблица кодов ASCII
ASCII таблица кодов символов Windows (Win-1251)
|
|
Расширенная таблица кодов ASCII
Символы форматирования.
|
Backspace (Возврат на один символ). Показывает на движение механизма печати либо курсора дисплея назад на одну позицию. |
|
|
Horizontal Tabulation (Горизонтальное Табулирование). Показывает движение механизма печати либо курсора дисплея до следующей предписанной "позиции табуляции". |
|
|
Line Feed (Перевод строки). Показывает движение механизма печати либо курсора дисплея к началу следующей строки (на одну строку вниз). |
|
|
Vertical Tabulation (Вертикальное Табулирование). Показывает движение механизма печати либо курсора дисплея к следующей группе строк. |
|
|
Form Feed (Перевод страницы). Показывает движение механизма печати либо курсора дисплея к исходной позиции следующей страницы, формы или экрана. |
|
|
Carriage Return (Перевод каретки). Показывает движение механизма печати либо курсора дисплея к исходной (крайней левой)позиции текущей строки. |
Передача данных.
|
Start of Heading (Начало Заголовка). Применяется для определения начала заголовка, который может содержать информацию о маршрутизации или адрес. |
|
|
Start of Text (Начало Текста). Показывает начало текста и одновременно конец заголовка. |
|
|
End of Text (Конец Текста). Применяется при завершении текста, который был начат с символа STX. |
|
|
Enquiry (Запрос). Запрос идентификационных данных (типа "Кто Вы?") от удаленной станции. |
|
|
Acknowledge (Подтверждение). Приемное устройство передает этот символ отправителю в качестве подтверждения успешного приема данных. |
|
|
Negative Acknowledgement (Неподтверждение). Приемное устройство передает этот символ отправителю в случае отрицания (неудачи) приема данных. |
|
|
Synchronous/Idle (Синхронизация). Применяется в синхронизированных системах передачи. В моменты отсутствия передачи данных система непрерывно посылает символы SYN для обеспечения синхронизации. |
|
|
End of Transmission Block (Конец Блока Передачи). Показывает конец блока данных для коммуникационных целей. Применяется для разбиения на отдельные блоки больших объемов данных. |
Разделительные знаки при передаче информации.
Другие символы.
|
Null. (No character- нет данных). Применяется для передачи в случае отсутствия данных. |
|
|
Bell (Звонок). Применяется для управления устройствами сигнализации. |
|
|
Shift Out. Показывает, что все последующие кодовые комбинации должны интерпретироваться согласно внешнему набору символов до прихода символа SI. |
|
|
Shift In. Показывает, что последующие кодовые комбинации должны интерпретироваться согласно стандартному набору символов. |
|
|
Data Link Escape (Переключение). Изменение значения идущих следом символов. Применяется для дополнительного контроля или для передачи произвольной комбинации бит. |
|
|
DC1, DC2, DC3, DC4 |
Device Controls (Контроль Устройства). Символы для управления вспомогательными устройствами (специальными функциями). |
|
Cancel (Отмена). Показывает, что данные, которые предшествовали этому символу в сообщении или блоке, должны игнорироваться (обычно в случае обнаружения ошибки). |
|
|
End of Medium (Конец Носителя). Указывает на физический конец ленты или другого носителя информации |
|
|
Substitute (Заместитель). Применяется для подмены ошибочного или недопустимого символа. |
|
|
Escape (Расширение). Применяется для расширения кода, указывая на то, что последующий символ имеет альтернативное значение. |
|
|
Space (Пробел). Непечатаемый символ для разделения слов или перемещения механизма печати или курсора дисплея вперед на одну позицию. |
|
|
Delete (Удаление). Применяется для удаления (стирания) предыдущего знака в сообщении |
|
Код (двоичный) |
(десятичный беззнаковый) |
(десятичный знаковый) |
|
|
А (большое латинское) | |||
|
B (большое латинское) | |||
|
a (малое латинское) | |||
|
А (большое русское) В кодировке ANSI | |||
|
А (большое русское) В кодировке ASCII |
Подобный код, как показано выше, соответствует также целому числу от 0 до 255 в беззнаковом (unsigned) формате. Таким образом, каждому символу соответствует целое число, также называемое кодом символа. Совокупность кодов символов называется кодовой таблицей или кодировкой .
Для персональных компьютеров наиболее распространены кодовые таблицы ANSI (American National Standard Institute) и ASCII (American Standard Code for Information Interchange). Таблица ANSI применяется в Windows, а ASCII применялась в DOS. Однако в этих двух таблицах первые 128 кодов (от 0 до 127) совпадают ; они различаются лишь последующими 128 кодами, используемыми для хранения национальных (русских) букв и символов "псевдографики".
В приведенных таблицах обозначение КС означает "код символа", а С – "символ".
Стандартная часть таблицы символов (ascii-ansi)
Некоторые из вышеперечисленных символов имеют особый смысл. Так, например, символ с кодом 9 обозначает символ горизонтальной табуляции, символ с кодом 10 – символ перевода строки, символ с кодом 13 – символ возврата каретки.
1.8 Алгоритмы защиты, выполняемые БМРЗ
1.8.1 Трехступенчатая максимальная токовая защита (МТЗ) от междуфазных повреждений с контролем тока в двух или трех фазах (Код ANSI ) 50 ). Возможность выбора одной из четырех зависимых времятоковых характеристик. Возможность выполнения направленной МТЗ (Код ANSI 67 ), МТЗ с комбинированным пуском по напряжению ) (Код ANSI 51 V ), с коррекцией по напряжению прямой последовательности, МТЗ по фантомному напряжению. Автоматический ввод ускорения МТЗ при любом включении выключателя. Две программы МТЗ по уставкам и программным ключам.
1.8.2 Быстродействующая направленная защита (Код ANSI 67 ) от всех видов коротких замыканий с блокировкой по высокочастотному каналу или волоконно-оптической линии связи на воздушных линиях, не имеющих пофазного управления выключателем.
1.8.3 Направленная или ненаправленная защита от однофазных замыканий на землю (ОЗЗ) (Код ANSI 64 ), действующая на отключение и/или на сигнализацию с двумя выдержками времени. Регистрация высокочастотных составляющих в токе нулевой последовательности. Две программы уставок (Код ANSI 50 G / N ).
1.8.4 Защита от несимметрии и от обрыва фазы питающего фидера (ЗОФ) (Код ANSI 46 ).
1.8.5 Защита минимального напряжения (ЗМН) (Код ANSI 27 ).
1.8.6 Логическая защита шин 6-10 кВ (ЛЗШ) (Код ANSI 68 ).
1.8.7 Дальнее резервирование (ДР) при отказе защит или выключателей.
1.8.8 Защита от снижения напряжения (ЗСН) при включении выключателя (Код ANSI 27 ).
1.8.9 Защита от повышения напряжения (ЗПН) (Код ANSI 59 ).
1.8.10 Дистанционная защита (ДЗ)(Код ANSI 21 ).
1.8.11 Минимальная токовая защита электродвигателей (Мин ТЗ) (Код ANSI 37 ).
1.8.12 Токовая защита нулевой последовательности (ТЗНП) (Код ANSI 51 N ).
1.8.13 Защита от неполнофазного режима (ЗНФР).
1.8.14 Дифференциальная защита трансформатора (Код ANSI 87Т ), в том числе:
Дифференциальная токовая защита с торможением (ДЗТ);
Дифференциальная токовая отсечка (ДТО).
1.8.15 Дифференциальная защита электродвигателя (Код ANSI 87М ), в том числе:
Дифференциальная токовая отсечка (ДТО);
Дифференциальная защита с торможением (ДЗТ);
Дифференциальная фазовая отсечка (ДФО).
1.8.16 Дифференциальная защита шин (ДЗШ) (Код ANSI 87ВВ ).
1.8.17 Защита от потери питания (ЗПП) (Код ANSI 27 / 59 ).
1.8.18 Защита от перегрузки (Код ANSI 49 ).
1.8.19 Контроль напряжения (цепей измерительного трансформатора напряжения; на шинах или в линии)
(Код ANSI 27 / 59 ).
1.8.20 Контроль синхронизма напряжений (Код ANSI 25 ).
1.8.21 Защита от блокировки ротора (Код ANSI 48 ) и затянутого пуска двигателя (ЗБР) (Код ANSI 14 ).
1.8.22 Тепловая модель электродвигателя (ТМ) (Код ANSI 49 ).
1.8.23 Защита по обратной мощности (Код ANSI 32 P ) и/или реактивной мощности (Код ANSI 32 Q ).
1.8.24 Защита электромагнитов управления выключателя.
1.8.25 Контроль завода пружин.
1.8.26 Выполнение команд дуговой защиты от внешних устройств.
1.8.27 Выполнение команд газовой защиты от внешних устройств (Код ANSI 63 ).
1.8.28 Выполнение команд контроля давления элегаза от внешних устройств.
1.9 Алгоритмы автоматики
1.9.1 Определение направления мощности (ОНМ) (Код ANSI 67 / 50 / 51Р ) для направленной МТЗ или
для автоматического переключения программ МТЗ и ОЗЗ.
1.9.2 Двукратное или однократное автоматическое повторное включение (АПВ) (Код ANSI 79 ).
1.9.3 Резервирование при отказе выключателя (УРОВ) (Код ANSI 50 BF ).
1.9.4 Автоматическое включение резерва (АВР).
1.9.5 Определение места повреждения(ОМП).
1.9.6 Выполнение команд автоматической частотной разгрузки (АЧР) и автоматического повторного включения по
частоте (ЧАПВ) от внешнего устройства частотной разгрузки.
1.9.7 Автоматическая частотная разгрузка (АЧР).
1.9.8 Ограничение количества пусков двигателя (ОКП) (Код ANSI 66 ).
1.9.10 Управление электроприводами устройств регулирования напряжения трансформаторов под нагрузкой.
1.9.11 Управление короткозамыкателем и отделителем .
1.10 Алгоритмы управления
1.10.1 Отключение и включение выключателя внешними командами и кнопками на лицевой панели.
1.10.2 Оперативный ввод/вывод функций защиты и автоматики по внешним сигналам.
1.10.3 Дистанционное изменение параметров настройки.



